
Underwriting is central to insurance, determining risk acceptance, pricing, and profitability. Many insurers still rely on slow, manual processes, fragmented data, and time-intensive decision cycles, hindering their ability to handle modern risk complexity and meet customer demand for speed and tailored coverage.
Unstructured submissions and dispersed data force underwriters to focus on data preparation, not decision-making. AI underwriting uses machine learning and automation to transition from sequential, manual methods to scalable, data-driven decision systems.
At Sun*, we work with insurers to operationalize this shift-designing AI-driven underwriting pipelines that integrate with existing data stacks.
In this article, we break down what AI underwriting is, where traditional approaches fall short, and how machine learning transforms each step of the underwriting process.
Key summary
- From Bottlenecks to Intelligence: AI replaces manual document intake and “data lag” with machine learning models that infer risk patterns from historical data at superior speed and scale.
- Modular Automation: Distinct AI capabilities streamline the entire underwriting lifecycle from triage to decisioning, allowing for both fully automated processing and AI-assisted complex analysis.
- Compounding Value: By decoupling growth from headcount, AI delivers faster cycle times, more consistent decisions, and lower loss ratios.
What Underwriting means for the modern insurance data stack?
Underwriting is a key financial process where individuals or institutions assume financial risk for a fee, primarily in loans, insurance, and investments.
At its core, the process of evaluating risk is to determine whether and at what price an insurer will extend coverage. Every policy issued begins with a question: how likely is this applicant to generate a claim, and what premium adequately prices that probability?
The core function of an underwriter is to rigorously assess risk. This involves a data-intensive but structured process. To reach a decision, underwriters review the initial application and loss history, analyze third-party information (such as motor vehicle records, credit reports, property inspection data, and telematics feeds) and then apply a mix of professional judgment, proprietary guidelines, and actuarial tables.
The sheer volume of data is significant; even a relatively simple commercial application may require consulting numerous data sources before a quote can be issued.
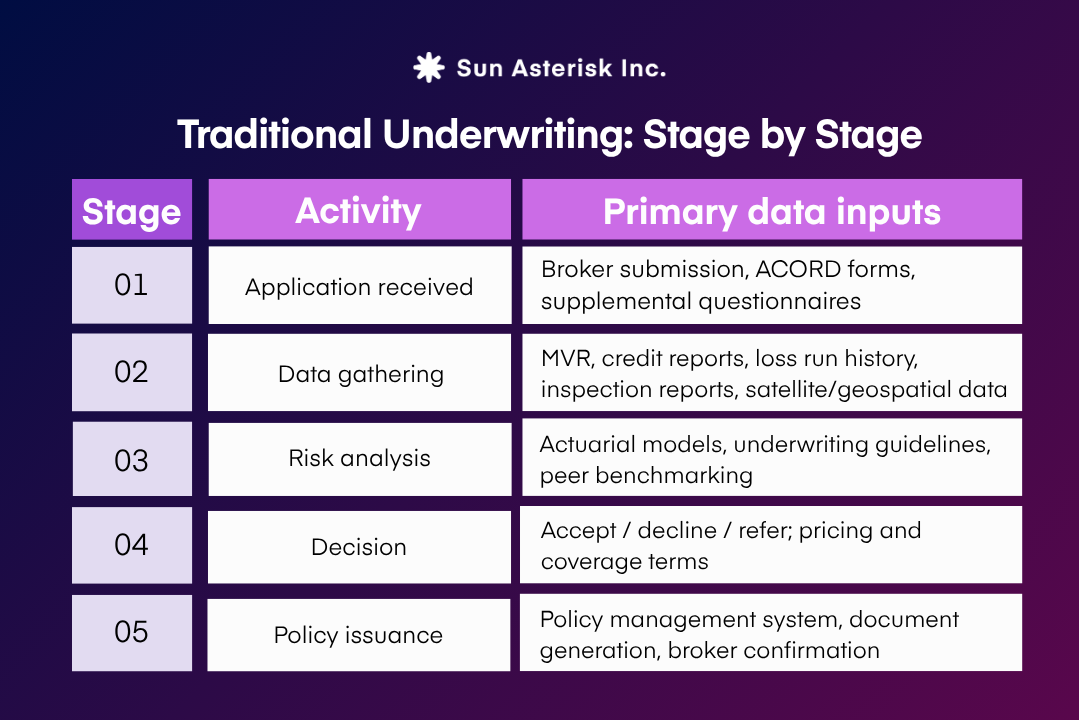
On paper, a clean linear flow. In practice, each stage involves data that arrives in different formats, at different speeds, from systems that rarely talk to each other. That gap is where modern insurers are losing time and money.
Where traditional underwriting breaks in insurance
1. Reliance on backward-looking, static data
The foundational models of classical underwriting rest on a critical assumption: that risk is stationary and historically predictable.
By repeatedly asking “what happened in the past?” rather than “what is most likely to happen next?”, these actuarial frameworks are structurally incapable of anticipating emerging risk profiles.
This limitation compounds over time. Consumer behaviour is shifting faster than annual policy cycles can capture. Climate patterns, geopolitical volatility, and technological disruption are introducing risk dynamics with no reliable historical precedent.
2. Inability to price systemic and AI-driven risks
Traditional models are fundamentally unequipped to price systemic or rapidly evolving risks. This is because they are anchored to historical loss distributions, which means they struggle with categories where correlation is high, precedent is thin and the threat itself is actively adapting.
In property and casualty, historical loss models are buckling under climate exposures that defy prior frequency-severity assumptions. In cyber insurance, the breakdown is even more acute.
The advent of GenAI-powered attacks is making threat vectors like business email compromise significantly more dangerous, while ransomware attacks showed a significant year-over-year increase of approximately one quarter in 2024, with data exfiltration nearly doubling over the same period.
Standard actuarial cycles – operating on annual reviews – cannot track threats that mutate within weeks. The result is chronic mispricing: traditional pricing models consistently underestimate exposure to AI-powered attacks, in some high-risk scenarios leaving insurers underpriced by an estimated 25–35%.
3. Manual inefficiencies and high error rates
The legacy underwriting workflow is slow by design: lengthy questionnaires, sequential data requests, manual cross-referencing, and document-by-document review before any risk analysis can begin.
Operating model drives significant labour costs while creating a submission backlog that historically averages three days just to underwrite a standard policy. For complex commercial submissions, the cycle stretches to weeks.
Beyond speed, the reliance on human-led data entry and manual investigation carries an inherent error rate. Transcription mistakes, missed fields, and inconsistent data capture across underwriters each introduce noise into the risk profile that downstream pricing models then treat as signal.
The problem is not underwriter competence; it is that the architecture forces highly skilled professionals to spend 40–60% of their time on administrative data assembly rather than the risk judgment they were hired to apply.
4. Vulnerability to sophisticated fraud
Manual underwriting controls struggle against the scale and sophistication of modern fraud. Legacy processes, treating each application in isolation, fail to detect coordinated anomalies, subtle misrepresentations, or evolving identity fraud.
Ghost broking, for instance, thrives because human underwriters, working under pressure, miss the network-level signals of fraud. This challenge is worsened by deepfake-powered synthetic identity fraud, creating credentials that manual review cannot reliably detect.
5. Perpetuation of historical bias
Traditional underwriting often relies on variables like ZIP codes, credit scores, and education levels which—while actuarially neutral on the surface—can act as proxies for race or socioeconomic status. For example, studies have shown that drivers in predominantly Black ZIP codes can face insurance premiums as much as 30% higher than those in white neighborhoods with similar risk profiles.
As regulators introduce stricter standards to address these disparities, AI underwriting in insurance provides a path toward greater transparency and objectivity. Unlike manual processes that are structurally ill-equipped for rigorous bias testing, audited AI systems allow insurers to identify and remove discriminatory correlations, ensuring models meet modern regulatory requirements while maintaining pricing accuracy.
What is AI Underwriting for Insurance?
Machine learning models work differently. Trained on historical claim and policy data, they infer which combinations of variables, including interactions that no human analyst would think to specify, are predictive of future loss.

AI underwriting automation varies. Simple personal risks are suitable for Straight-Through Processing (STP), while complex commercial risks continue to require underwriter judgment, with AI serving as an intelligence layer.
How AI Replaces Each Manual Step
Step 1. NLP & LLMs for Intelligent Document Intake
Historically, document handling was the “silent killer” of productivity, often consuming up to 80% of an adjuster’s or underwriter’s bandwidth. The emergence of Natural Language Processing (NLP) and Large Language Models (LLMs) has evolved the standard beyond simple scanning.
By flipping the ratio, manual handling drops to just 20%, allowing the cycle to collapse from a 30-day legacy baseline to an agile 7.5-day average.
Step 2. AI-Orchestrated Data Enrichment
By orchestrating AI to ingest streaming data like telematics, IoT home sensors, and geospatial imagery, insurers can build a 360-degree risk profile in the background. Automated pre-fill capabilities remove the burden of proof from the customer, reducing the time-to-quote by 30% to 40%.
Step 3. ML Classifiers for Intelligent Triage and Routing
Modern ML classifiers act as a sophisticated filter, scanning texts and behavioral signals to flag anomalies. These systems typically improve fraud detection rates by over 30% while simultaneously reducing false positives by 40%.
Step 4. Predictive Models for Dynamic Risk Scoring
Instead of relying on rigid, historical “buckets,” these models generate hyper-personalized risk profiles. This facilitates a paradigm shift toward continuous underwriting, reflecting the customer’s actual, current risk level.
Step 5. Automated Decisioning and Autonomous Execution
By integrating AI as the core decision-maker for standard risk profiles, the final approval is an instant result of the data flow. We are seeing the underwriting timeline collapse from 3 days to just 3 minutes.
Ready to explore AI underwriting for your organization?
Sun*’s insurance technology team collaborates with carriers and MGAs to develop and implement AI underwriting solutions.





