
Early systems for fraud detection and prevention in banking industry were built on static rules, including blocking high-value transactions or flagging activity from unfamiliar locations.
While this rule-based approach offers a sense of control and works for low transaction volumes where teams can manually define patterns, its rigidity causes it to break down as transaction volume increases and fraud tactics become more sophisticated.
The scale of the problem makes this urgency concrete: the US Federal Trade Commission reported that consumers lost more than $12.5 billion to fraud in 2024- a 25% jump from the previous year. Separately, 79% of organizations were victims of payments fraud attacks or attempts in 2024.
After working with hundreds of payments teams, we found that the fundamental issue is that rules are static representations of past knowledge, while fraud is dynamic. In this article, we will show how modern ML-powered fraud detection systems maintain it at scale, in under 200 milliseconds.
Key summary
- Real-time fraud detection is a scoring pipeline, not a single model, operating within a 50-200ms authorization window.
- XGBoost is dominant due to its ability to handle imbalanced data, fast CPU inference, and high precision-recall, often stacked with Graph Neural Networks and recurrent models for comprehensive coverage.
- Achieving sub-200ms inference is an architecture challenge solved by pre-computation: feature stores deliver enriched data quickly, and models are loaded into memory and served via low-latency endpoints, maintaining p95 latency between 60–80ms.
What Is Real-Time Fraud Detection?
Real-time fraud detection is the practice of evaluating each transaction against a predictive model the moment it is initiated – assigning a fraud risk score before the payment authorization response is returned to the merchant or user.
The definition sounds simple. The engineering constraint is not.
In practice, most mature systems target under 50ms at the scoring layer, leaving a budget for network latency, feature enrichment, and downstream action logic.
This constraint changes everything about how you architect the system. A model that achieves 99.9% AUC on your validation set is worth nothing if it takes 800ms to run inference. Latency is not a performance metric, it is a hard product requirement.
Timing is not a technical preference in fraud detection, it is the product requirement. On instant-payment rails or domestic e-wallet networks, transactions settle irreversibly in seconds. By the time a batch review flags a suspicious pattern, the money has already moved.
Beyond financial loss, a slow or miscalibrated system creates a second problem: false positives. Legitimate customers declined at checkout churn at measurably higher rates, turning a fraud tool into a revenue liability.
Real-time detection – scoring every transaction before authorization completes – is the only architecture that prevents fraud before it happens, rather than documenting it afterward.
Moving beyond limited rule-based systems to scalable Machine Learning
Rule-based fraud detection systems rely on static rule engines, pre-defined thresholds, and binary logic – making them increasingly inadequate for modern, high-volume financial networks.
The fundamental limitation is that rules are linear: they evaluate one condition at a time, applied sequentially. A sophisticated fraudster simply reverse-engineers those conditions and operates just inside the boundary. 04 structural failures emerge as scale increases:
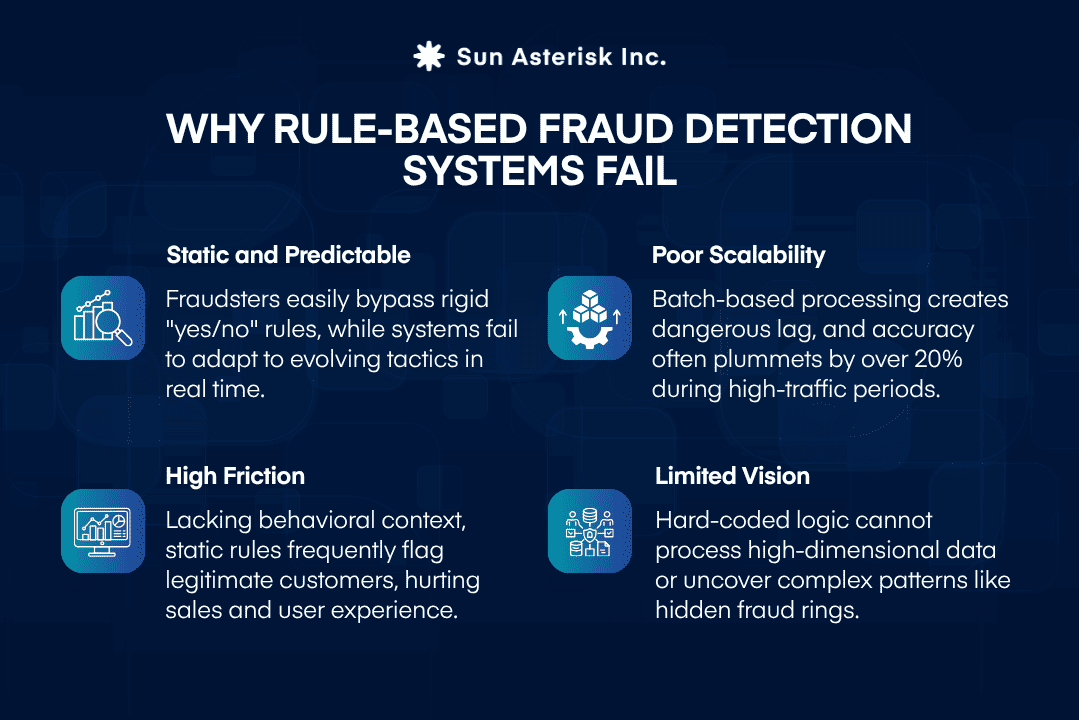
Fraud detection and prevention in banking industry shifts from rigid rules to adaptive defense. Rather than one condition, ML models evaluate combined signals (amount, location, behavior) to learn “normal” user patterns and flag anomalies.
Through retraining on feedback, models adjust to new patterns without manual updates. Architectures like Graph Neural Networks even uncover complex fraud rings invisible to rules. The result is a more accurate system: ML outperforms rules on precision-recall benchmarks and evolves automatically; when fraud changes, the model retrains rather than waiting for human intervention.
Choosing the right ML models for high-speed fraud analysis
No single model architecture dominates production fraud detection. The right choice depends on transaction volume, feature complexity, latency budget, and interpretability requirements.
| Model Type | Primary Strengths | Key Limitations | Best Fit |
| Gradient Boosted Trees (XGBoost, LightGBM) | High accuracy on tabular data; fast inference; handles missing values well | Requires feature engineering; limited on sequential data | Core scoring model for most production systems |
| Logistic Regression | Extremely fast inference; fully interpretable; easy to audit | Cannot capture non-linear feature interactions | Baseline model; regulatory contexts requiring explainability |
| Neural Networks (MLP, Autoencoders) | Learns complex non-linear patterns; strong on high-cardinality features | Harder to interpret; higher latency; needs large data volumes | Anomaly detection; embedding generation for behavioral features |
| Recurrent / Transformer Models | Captures sequential transaction behavior; detects velocity patterns | High inference latency; complex to deploy at scale | User behavior modeling; post-transaction risk enrichment |
| Graph Neural Networks | Detects network-based fraud rings; links accounts through shared signals | Expensive to compute; requires graph infrastructure | Identity fraud, synthetic accounts, money mule detection |
| Ensemble / Stacked Models | Combines strengths of multiple architectures; typically highest accuracy | Complex to maintain; cumulative latency risk | High-value transaction channels where accuracy justifies complexity |
Most mature platforms run gradient boosted trees as their primary scoring model, augmented by neural network-generated behavioral embeddings fed as features. Graph-based signals are increasingly added as a third layer for account-level fraud detection.
This multi-layer approach reflects a broader industry trend: 2/3 of merchants are currently using or plan to use generative AI in fraud management within the next 12 months.
How ML Models Score Transactions in Milliseconds
Modern fraud detection has evolved from retrospective batch processing to real-time, event-driven architectures.
By leveraging a stack of Apache Kafka, Flink, and Redis, these systems enrich and evaluate massive data streams as they happen. The most advanced frameworks, like MIND, push intelligence directly into the network’s data plane – executing ML models within programmable switches to stop fraud in microseconds, bypassing traditional server latency entirely.
Feature Extraction (Data Layer): Raw transactions are instantly enriched with behavioural signals – rolling velocity counts, geographic mismatches, burst detection, unique merchant counts. Automated Feature Engineering generates hundreds of historical features without manual encoding. In-memory feature stores serve these pre-computed values in single-digit milliseconds, eliminating disk I/O and solving train-serve skew.
Model Inference (Scoring Layer): The feature vector is scored by a lightweight, inference-optimised model held entirely in memory. XGBoost achieves p95 latencies of 60–80ms on standard cloud instances; endpoints scale horizontally for traffic spikes. In ultra-low-latency environments, decision trees decompose into hardware match-action rules, letting the network switch itself score the transaction as the packet passes through.
Decision Threshold (Risk Strategy Layer): The model generates a 0-to-1 probability score, which the risk strategy converts into an action. Scores >0.80 auto-decline; 0.50–0.80 trigger step-up authentication (like OTP/biometrics); <0.50 are approved. Advanced systems use Reinforcement Learning to dynamically adjust these thresholds, enabling real-time response to attacks or concept drift without manual recalibration.
Action & Feedback Loop (Execution): The decision returns to the authorisation flow synchronously. Asynchronously, every outcome confirmed fraud or declined legitimate customer is logged into a retraining pipeline. The system learns continuously from its own mistakes, adapting to adversarial tactics without a manual retraining cycle.
Maintaining model integrity in a high-speed production environment
A fraud model that performs well in validation can silently degrade in production within weeks. Deployment is not the finish line, it is where the operational complexity begins.
How model drift begins to impact accuracy the moment you deploy
In the real world of financial applications, fraud patterns are not static. Fraudsters constantly innovate their tactics, such as launching account takeover (ATO) attacks, deploying new spoofing patterns, or creating expansive, multi-hop mule networks.
As these behaviors evolve, fraud detection and prevention in banking industry models experience concept drift, meaning the underlying data distributions change and accuracy degrades over time. To counter this, continuous monitoring uses change-point detection methods like PSI and Kolmogorov-Smirnov tests. Detecting shifts in transaction data automatically triggers alerts and retraining for optimal performance.
Advanced systems also use Reinforcement Learning (RL) to dynamically adjust scoring thresholds based on real-time feedback, enabling autonomous adaptation to sudden behavioral changes or attack spikes without full retraining delays.
Breaking the cycle of the false positive feedback loop
Ground truth in fraud detection arrives late. A fraudulent transaction is typically confirmed days or weeks after it occurs through a chargeback, a customer dispute, or an investigation.
This label delay creates a structural gap for fraud detection and prevention in banking industry pipelines: the most recent transactions, which are the most relevant for current attack patterns, are also the least labelled. Models retrained on stale labels systematically underperform on emerging vectors.
Teams must account for this explicitly-using techniques like semi-supervised learning, conservative label propagation, or time-windowed training sets that discount recent, unlabelled data rather than treating its absence as legitimate.
Testing in the shadows to ensure production safety during rollout
Deploying a real-time ML model that evaluates transactions in milliseconds carries immense operational risk. Before a new or updated model goes live to actively block transactions, it must undergo rigorous validation to ensure it does not catastrophically fail or freeze legitimate accounts.
To deploy safely, institutions utilize the following strategies:

If you’re evaluating your fraud detection architecture, whether greenfield or migrating from a rule-based legacy system, we’d welcome a technical conversation.
Sun’s engineering teams have deep experience designing real-time ML systems for financial services worldwide.
👉 Talk to our team





