The pressure on healthcare operations has never been more acute. According to the AAMC Report, with the U.S. facing a projected shortage of 124,000 physicians by 2034, emergency departments manage over 155 million visits annually.
More than half of hospitals operating on margins below 1.1%, health system leaders are under structural pressure that incremental fixes can no longer absorb.
For every successful deployment, dozens more organizations are sitting on stalled pilots and underused tools that promised transformation but delivered a dashboard.
The landscape has shifted decisively. Agentic AI in healthcare has emerged as the new operational benchmark, replacing the generative tools that dominated 2023-2025.
Human-in-the-loop healthcare automation has become a procurement requirement, not an ethical preference. And the bar for proving healthcare AI ROI has risen sharply – cost-saving projections alone no longer satisfy clinical boards who have seen the gap between vendor promises and real-world outcomes.
Choosing AI for healthcare operations that actually lasts requires a different kind of evaluation. In this article, we’ll show you the framework we use to help organizations evaluate AI the right way.
Key summary
- The Paradigm Shift: Moving from “Generative AI” (chatbots) to “Agentic AI” (autonomous task execution).
- The Human Element: Why “Human-in-the-Loop” (HITL) is the gold standard for safety and staff retention.
- Value Metrics: Shifting ROI from simple cost-savings to “Time-to-Care” and “Outcome-Yield.”
- Selection Framework: A 5-point checklist for vetting clinical-grade AI.
Why Generative AI is no longer enough?
Generative AI gave healthcare a better way to write. But hospitals spend roughly 20% of their budgets on administrative tasks that require action, tracking, and follow-through – not just smarter text. By 2026, 85% of healthcare leaders plan to increase investment in agentic AI: systems that don’t just inform, but execute.
Two years ago, the buzz word was a possibility. Vendors demoed large language models that could summarize discharge notes, draft prior auth letters, and flag anomalous lab trends. Healthcare executives, rightly dazzled, opened budgets. Pilots launched. Newsletters celebrated.
Then the pilots ended and most of the tools didn’t stick.
We are now in a fundamentally different era. The question is no longer “What can AI do?” – it is “How does AI stay?” Sustainability, not spectacle, is the competitive differentiator. And that shift is forcing a rethink of what “good AI” actually means in a clinical operations context.
The rise of Agentic AI in healthcare
Agentic AI in healthcare is the term now dominating the procurement conversations of health system CIOs and CMIOs.
Unlike generative models that produce outputs requiring human action to execute, agentic systems can autonomously initiate and complete multi-step workflows. Think: an AI that doesn’t just flag a denied claim – it re-routes it through the appeals process, attaches clinical supporting documentation, and tracks resolution status, notifying a billing specialist only when a human judgment call is truly required.
This distinction is profound for operations. Revenue cycle leakage, prior authorization bottlenecks, supply chain disruptions, these are not problems that benefit from smarter suggestions. They benefit from fewer handoffs.
Read more: Top 05 Agentic AI Use Cases in Healthcare Clinical Workflows
Human-in-the-Loop automation in healthcare
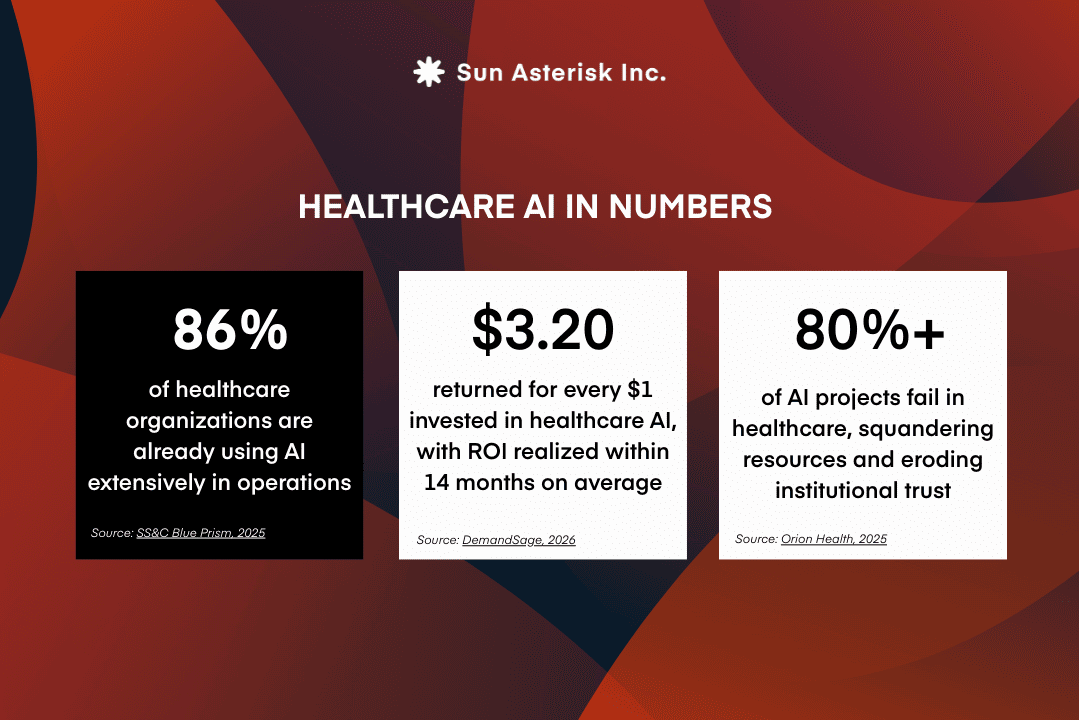
Simultaneously, the specter of workforce replacement – never far from the healthcare AI conversation – has evolved into a more sophisticated concern: workforce augmentation.
With nursing vacancy rates persistently high and physician burnout at record levels, the last thing healthcare organizations need is AI that erodes the roles people actually want to keep.
Human-in-the-loop healthcare automation where AI handles repetitive, high-volume tasks while escalating ambiguous or high-stakes decisions to qualified clinicians has moved from ethical preference to operational necessity.
Measuring AI ROI in the Agentic era
Cost reduction was the original promise and it remains relevant. But in 2026, the healthcare AI ROI conversation has matured. Health system finance leaders have watched enough failed pilots to know that “cost savings” projections from AI vendors are frequently based on theoretical throughput models that don’t survive first contact with a real clinical environment.
A more rigorous healthcare AI ROI framework measures value across four dimensions that reflect actual operational health:
| Value Dimension | What to Measure | Why It Matters |
|---|---|---|
| Clinical Throughput | Cases processed per FTE, documentation time per encounter | Indicates whether AI is genuinely freeing clinician capacity |
| Staff Augmentation | Reduction in overtime, improvement in retention metrics | Workforce stability is a direct financial and quality variable |
| Revenue Integrity | Prior auth approval rates, claim denial rates, days in A/R | Measurable, auditable, and directly tied to AI intervention points |
| Safety & Quality | Adverse event rates, readmission within 30 days, protocol adherence | Clinical quality outcomes signal whether AI is helping or introducing risk |
How to choose AI solution for healthcare operations
Demand proof of clinical workflow integration, not just EHR compatibility
When evaluating AI solutions for healthcare operations, the most important question solution providers rarely answer directly is: where, exactly, does the intelligence appear?
Not in theory – in the actual environment where clinicians make decisions. This distinction matters because vendors routinely conflate two very different things: connecting to an EHR system and integrating into clinical workflow. The first is a technical milestone. The second is what determines whether a tool gets used.
The gap between the two is well-documented. Despite nearly universal EHR adoption – 96% of U.S. hospitals now use certified systems and only 44% of clinicians report that their EHR integrates well with outside systems, and just 30% of healthcare organizations have achieved full interoperability.
“EHR-compatible” typically means a system can access data through an API. It does not mean insights surface inside the patient chart, at the moment a decision is being made.
This distinction has real consequences for adoption. AI that lives outside the clinical workflow rarely gets used. Decision support tools requiring clinicians to open a separate dashboard or navigate away from the patient chart quickly become another administrative burden rather than a clinical asset.
Research consistently shows that seamless workflow integration ranks as physicians’ top requirement for trusting AI above privacy assurances, above additional training. Even highly accurate models fail to gain traction when they introduce friction at the point of care.
For healthcare leaders, this means evaluation must go beyond compatibility claims. The critical question is not whether a platform connects to the EHR, but whether its intelligence appears inside the clinical workflow itself surfacing recommendations and insights naturally, in real time, without requiring clinicians to manage another layer of technology.
That requires looking past marketing language and examining how a system actually functions in the environment where care is delivered.

Evaluate the human-in-the-loop design before the algorithm
By 2026, HITL oversight has become a near-universal claim and precisely because of that, it has become one of the least useful signals in an AI evaluation.
Having worked alongside clinical teams implementing AI in real healthcare environments, we’ve observed that the gap between claiming HITL support and designing it well is where most deployments succeed or fail.
In principle, HITL ensures AI augments rather than replaces clinical judgment. In practice, the quality of implementation varies widely and the failure modes run in opposite directions. Under-automation floods clinicians with alerts; over-automation allows high-risk cases to pass without review.
Neither problem surfaces in a product demo, but both emerge quickly in real clinical workflows. A 2025 systematic review in the International Journal of Medical Informatics confirmed this pattern: while HITL systems can improve diagnostic accuracy and reduce medical errors, alert fatigue remains a major failure point even in well-designed deployments.
Separately, studies show that properly calibrated AI can reduce medication alert volumes by up to 54% – a figure that illustrates just how consequential the difference between thoughtful and poorly tuned HITL design can be.
What we’ve consistently found is that escalation threshold management is the detail that separates deployments clinicians trust from ones they route around.
Experts at the 2025 Penn Medicine AI Symposium identified threshold management as one of the most consequential and least discussed dimensions of clinical AI deployment. It rarely appears in feature comparisons, but it determines whether the human-in-the-loop is a genuine safety mechanism or an afterthought.
For healthcare organizations evaluating AI solutions, the critical question is not simply whether humans are “in the loop,” but who controls when the loop activates.
Require explainability at the patient level
A probability score is not an explanation and healthcare organizations evaluating AI solutions need to hold that line clearly.
The clinical stakes of this gap are well-established. Research published in JMIR found that the “black box” nature of many algorithms leads clinicians to question their value but the inverse is equally dangerous: excessive trust in unexplained AI recommendations can reduce clinical accuracy just as much as distrust. A 2025 review reinforced this, finding that explainable AI is consistently among the strongest predictors of clinician trust in clinical decision support systems.
Without that transparency, AI tends toward one of two failure modes ignored or blindly followed – both of which increase clinical and regulatory risk. As oversight from agencies like the U.S. Department of Health and Human Services continues to evolve, the ability to audit and explain AI-driven decisions is becoming an operational requirement, not just a best practice.
For organizations evaluating AI solutions, explainability cannot be assessed from a feature list. It requires seeing how a system communicates its reasoning in real clinical scenarios. The most credible systems translate model output into a clinically interpretable narrative tied to the individual patient, not a technical model report, and not a confidence percentage without context.
Ask for clinical evidence, not just tech credentials
Technical credibility does not guarantee clinical effectiveness. Certifications like ISO standards or SOC 2 compliance have become baseline expectations, but they reveal little about how an AI solution performs in terms of real-world outcomes.
Evidence shows that performance varies widely by use case. A 2025 survey in the JAMIA across 43 U.S. health systems found deployment success rates of 53% for ambient documentation, 38% for clinical risk stratification, and just 19% for imaging AI—a gap that aggregated vendor performance claims often obscure.
For organizations trying to choose the right AI solution for healthcare operations, this variation is critical. An AI solution that performs well in an academic medical center may underperform in community hospitals with different patient populations, workflows, or EHR configurations.
Vendor case studies and internal validation cohorts rarely capture these realities. In healthcare, every AI solution should be evaluated like any clinical intervention: through independent, peer-reviewed evidence in comparable real-world environments.
Ultimately, the most reliable signal of credibility is not the sophistication of the technology but the transparency of its evidence. Healthcare leaders should be able to identify who evaluated the AI solution, in which patient population, and with what outcome measures, ideally supported by published research rather than marketing materials.
Why Healthcare Leaders Must Stress-Test AI Before Deployment
Most healthcare AI initiatives do not fail because the algorithms are inaccurate, they fail because they never survive beyond the pilot phase.
Industry analyses estimate that over 80% of healthcare AI projects stall after initial pilots, largely because those pilots are designed to succeed under controlled conditions.
Models that perform well technically can still collapse once deployed in real workflows, where alert volumes overwhelm EHR inboxes or data quality deteriorates outside carefully curated datasets.
For organizations trying to choose AI solution for healthcare operations, this reality changes how pilots should be interpreted. Demonstrations and short-term trials often highlight best-case performance rather than operational resilience.
The real test of an AI system is how it behaves under everyday clinical pressures when staffing fluctuates, patient volumes surge, and frontline clinicians decide whether to trust or override the system’s recommendations.
Clear success metrics established before deployment prevent retrospective claims about performance, while defined failure thresholds give health systems the leverage to disengage if results do not hold under real-world conditions.
Ultimately, the most valuable pilots are those that deliberately expose weaknesses early before a promising technology becomes deeply embedded in clinical operations.

Choosing the right AI solution for healthcare operations is one of the most consequential decisions your organization will make this decade. At Sun*, we help healthcare teams cut through vendor noise, evaluate solutions against what actually matters – workflow fit, clinical evidence, and real ROI.
Book a consultation