
We’re living in the AI era, so as a healthtech leader, you might already know that manual sampling is no longer a viable healthcare audit risk scoring strategy.
In an era defined by a deluge of unstructured data from telehealth and remote monitoring, relying on human-only reviews leaves 99% of your data as “dark risk”, a blind spot that modern organizations can no longer afford.
For years, the industry chased “black box” metrics: a sepsis score, a risk percentage, a prediction with no backstory.
Billions were spent on models that told us what might happen and almost nothing about why.
The result?
Many of our clients shared that they have seen countless technically brilliant models sit on the shelf because a clinician (although quite rightly) refused to change a patient’s treatment plan based on a score they didn’t understand.
With the EU AI Act and the ONC’s HTI-1 Final Rule now in full effect, transparency isn’t just a clinical preference; it’s a regulatory mandate. We are moving past niche, complex pipelines and into a world where AI doesn’t just calculate a score—it tells a story.
We are shifting from “What is the risk?” to “Why is this happening, and what should we do about it?”
Key summary
This guide explores the transition from manual sampling to generative, explainable risk pipelines.
We’ll outline and discuss how healthtech leaders use RAG architecture and RegMLOps to achieve 100% audit coverage, ensuring regulatory compliance and clinical trust through transparent, real-time healthcare audit risk scoring.
Is manual sampling a hidden liability in healthcare audit risk scoring strategy?
For years, we’ve relied on the “look-back” audit like a retrospective, manual process that feels more like a post-mortem than a strategy.
In 2026, the delta between manual sampling and real-time healthcare audit risk scoring has become a chasm that separates thriving organizations from those drowning in clawbacks.
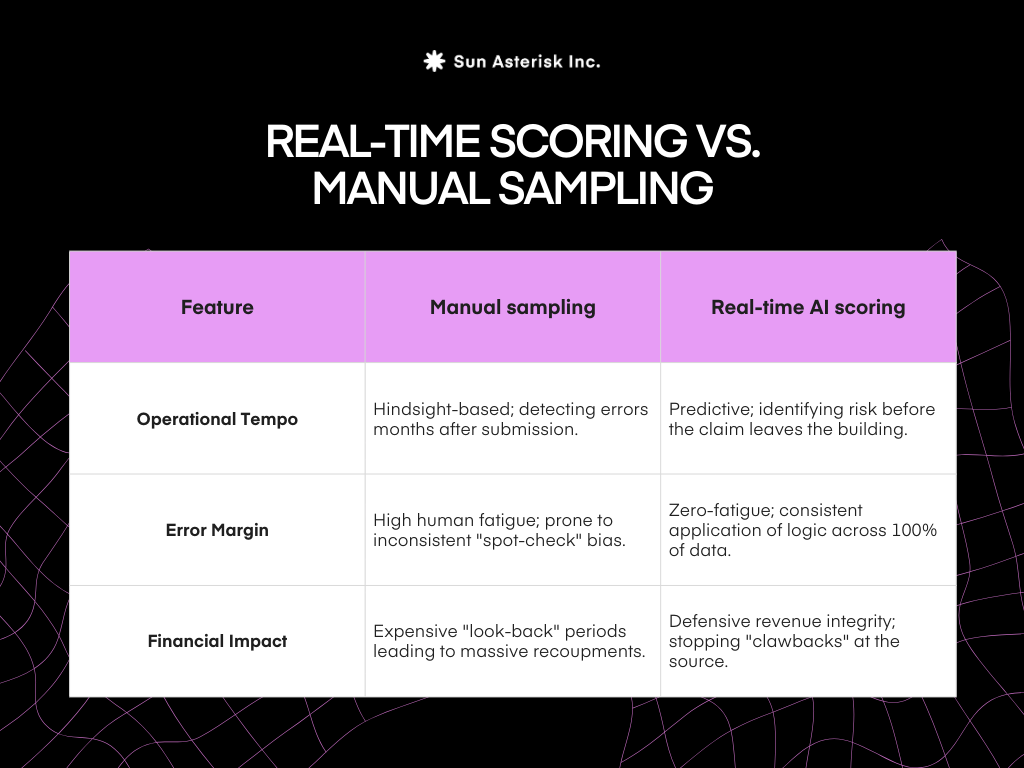
Real-time scoring transforms compliance from a cost center into a value protector.
Instead of spending your Q3 disputing thousands of Medicare Advantage DRG downgrades from Q1, your team is alerted to documentation gaps in the EHR workflow as they happen.
We are moving from a world of managing the damage to a world where we eliminate the exposure.
How do TEFCA expansion and AI transparency mandates redefine “audit readiness” today?
In the past, healthcare organizations could get away with telling regulators that their models were proprietary and high-performing.
Those days are gone.
The latest HHS and OCR transparency mandates have effectively forced us to “open the hood” of our AI.
→ What does it mean?
Regulators now care less about how “smart” your AI is and more about how honest it is.
If your system flags a patient’s chart as high-risk, you must be able to show exactly which piece of data led to that conclusion.
→ Our thought:
We aren’t just building software anymore; we are building a witness. If your healthcare audit risk scoring can’t explain itself to a human auditor, it’s not just a technical failure from your side but a legal one.
What does a “bulletproof” healthcare audit risk scoring actually look like today?
Being “audit-ready” in 2026 isn’t about having a clean office; it’s about having a digital receipt for every thought your AI had.
→ What does it mean? Imagine an auditor asks why a specific claim was flagged six months ago. You can’t just say “the AI updated its logic since then.”
You need a timestamped, version-controlled record.
This means showing the exact version of the model used, the exact rules in place that day, and the specific data that was analyzed.
→ Our thought:
True audit readiness is about reproducibility.
If you can’t recreate the “why” behind a decision from last Tuesday, you haven’t really audited it. We need to move from “fixing errors” to “documenting the logic” in real-time.
TEFCA and data liquidity
For years, leaders blamed “missing data” for inaccurate risk scores.
You might often hear “We didn’t know the patient saw a specialist in the next state,” as it was a common refrain.
TEFCA (the Trusted Exchange Framework and Common Agreement) has effectively deleted that excuse.
→ What has been change?
TEFCA acts like a universal adapter for healthcare data. It allows different hospitals, clinics, and insurance companies to securely “talk” to each other using the same language.
→How it helps risk scoring?
Because data can now flow across state lines and different health systems, our healthcare audit risk scoring pipelines can see the “full picture.” We can catch duplicate billings or conflicting diagnoses that were previously hidden in someone else’s database.
The technical blueprint for a generative risk pipeline
Building a pipeline that actually performs in a high-stakes clinical setting requires more than just a powerful model; it requires a structured path from raw data to a defensible conclusion.
To move beyond simple automation, we break the architecture down into 3 core layers that turn messy healthcare data into actionable intelligence.
First, we address data ingestion. And by this, we don’t mean just the scanning spreadsheets.
We are talking about the seamless conversion of FHIR (Fast Healthcare Interoperability Resources) and DICOM imaging data into a format the AI can actually digest.
This ensures the pipeline is looking at the same structured and unstructured clinical evidence that a human auditor would, creating a unified view of the patient’s journey.
Next is the RAG layer, which serves as the “fact-checker” of the system.
By using Retrieval-Augmented Generation (RAG), we ground every healthcare audit risk scoring result in specific, verified clinical guidelines—such as the latest CMS manuals or specific payer policies.
Instead of the AI “guessing” based on general training data, it is forced to “look up” the specific rule before it issues a flag.
Finally, we implement the reasoning engine.
This is the bridge between data and trust. We don’t just want a score; we want a narrative. The engine uses LLMs to write a human-readable executive summary for every flag.
It tells the auditor exactly why a record was flagged, which guideline was potentially violated, and what evidence was used to reach that conclusion. The goal is to make the AI’s “thought process” as clear as a peer-reviewed note.
Solving black box risks with the glass box approach
The biggest threat to AI adoption in healthcare isn’t a lack of accuracy: it is the “black box” problem.
When a model provides a high risk score without context, we face the triple threat of hallucinations, biased training data, and the ultimate failure point: clinicians and auditors ignoring the tool because of a “Because the AI said so” mentality.
To move toward a glass box approach, we focus on two critical avoidance strategies that protect both the patient and the organization.
The first strategy is strict grounding.
We solve the hallucination problem by limiting the AI’s search parameters. The model is only allowed to generate answers based on verified, uploaded policy documents.
This effectively turns the AI from a “creative writer” into a “precise librarian” who only cites established facts. If the answer isn’t in the manual, the AI doesn’t make it up.
The second strategy is the Human in the Loop (HITL) workflow.
We design the user interface so that an auditor can easily “Agree” or “Disagree” with an AI-generated score.
When a human expert corrects the AI, that insight is fed back into the system to refine future healthcare audit risk scoring. This transforms the AI from a mysterious judge into a collaborative partner that gets smarter and more aligned with your specific clinical standards every single day.
XAI frameworks for clinical precision
To achieve true clinical precision, we need tools that translate complex mathematical weights into human logic. This is where the Explainable AI (XAI) toolkit becomes essential for any healthcare audit risk scoring pipeline.

We start with SHAP and LIME, which provide feature-level transparency. Instead of a vague risk percentage, these frameworks show the specific “drivers” behind a score.
For example, a high-risk flag might be attributed specifically to “Patient Age,” “Chronic Comorbidity Markers,” and “Inconsistent ICD-10 Coding.” This allows an auditor to see exactly which variables tipped the scale, turning a statistical guess into a verifiable insight.
We then add Attention Maps to the mix. For unstructured data, like a five-page clinical note or a telehealth transcript, attention maps are a game-changer.
They visually highlight the specific sentences or phrases that triggered the risk flag. This allows a human reviewer to skip the “search” and go straight to the “evaluating,” seeing exactly where the AI spotted a discrepancy.
The ultimate goal here is to move from Predictive to Prescriptive.
We don’t just want to know what happened; we want to know why it happened and how we can fix it. By using XAI for digital patient engagement, we empower our teams to correct the root cause of a risk—whether that is a training gap for clinicians or a software glitch—rather than just flagging the symptom.
The final piece: the RegMLOps layer
You cannot build a sustainable risk pipeline in the healthtech era without a “compliance-as-code” layer. We call this RegMLOps. It is the operational backbone that ensures your AI remains as compliant as the data it analyzes.
The core concept of RegMLOps is that compliance shouldn’t be a manual check-up at the end of the year; it should be baked into the software’s DNA.
- Model Lineage: We need a clear, unalterable record of which model version made which decision, using which data. This is your insurance policy for when a regulator asks for a deep dive into a decision made months ago.
- Drift Detection. In healthcare, risk is a moving target. Payer rules change, and fraud schemes evolve.
Drift detection acts as an early warning system, alerting us the moment a model starts losing its edge or missing new types of anomalies. It ensures our healthcare audit risk scoring remains accurate even as the external environment shifts. - Finally, RegMLOps automates the Documentation for Regulators:
Instead of spending weeks preparing for an audit, the system generates real-time reports on model performance, bias testing, and logic grounding. It turns “audit readiness” from a high-stress event into a continuous, automated background process.
It’s time for engineering the narrative
We’re at the stage where the value of a healthtech solution is no longer measured solely by the accuracy of its predictions, but by the clarity of its explanations.
As architects and leaders, our job is to move beyond niche code and build ecosystems that speak the language of medicine. We are no longer just building risk scores; we are building evidence-as-a-service.
By providing 100% coverage with human-readable reasoning, we can finally stop guessing and start knowing. And when an AI can tell a patient’s story with the same nuance and clinical grounding as a human physician, we will finally have achieved the true goal of digital health.




